2024. 4. 28. 17:09ㆍ분산 ML
참고 자료 :
- https://tutorials.pytorch.kr/intermediate/dist_tuto.html#collective-communication
- 분산 학습과 집합 통신 :: 차근차근 - https://hadaney.tistory.com/39
- https://en.wikipedia.org/wiki/Collective_operation
PyTorch로 분산 어플리케이션 개발하기
Author: Séb Arnold, 번역: 박정환,. 선수과목(Prerequisites): PyTorch Distributed Overview. 이 짧은 튜토리얼에서는 PyTorch의 분산 패키지를 둘러볼 예정입니다. 여기에서는 어떻게 분산 환경을 설정하는지와 서
tutorials.pytorch.kr
Pytorch는 여러 process가 서로, 다같이 통신하는 방법으로 다음 6가지 방법을 구현해놓았다.
(두 process가 1대1로 통신하는 방법은 Point-to-Point 방식으로, 이 내용과 다르다!)
일단 이 집합통신(Collective Communication)은 월드(world) 라고 부르는 전체 프로세스 집합에서 실행된다.
Collective Operations (Collective Communication)
Collective Operation은 Parallel programming할 때 SPMD(Single Program, Multiple Data) 알고리즘에서 소통 방식(message passing)으로 자주 사용된다.
MPI (Message Passing Interface) 통신 표준에 의해 정의(?)됨.
PyTorch에는 다음과 같이 7개의 집합 통신이 구현되어 있다:
- `dist.broadcast(tensor, src, group)`: `src` 의 `tensor` 를 모든 프로세스의 `tensor` 에 복사.
- `dist.reduce(tensor, dst, op, group)`: `op` 를 모든 `tensor` 에 적용한 뒤 결과를 `dst` 프로세스의 `tensor` 에 저장.
- `dist.all_reduce(tensor, op, group)`: reduce와 동일하지만, 결과가 모든 프로세스의 `tensor` 에 저장.
- `dist.scatter(tensor, scatter_list, src, group)`: i번째 tensor `scatter_list[i]` 를 i번째 프로세스의 `tensor` 에 복사.
- `dist.gather(tensor, gather_list, dst, group)`: 모든 프로세스의 `tensor` 를 `dst` 프로세스의 `gather_list` 에 복사.
- `dist.all_gather(tensor_list, tensor, group)`: 모든 프로세스의 `tensor` 를 모든 프로세스의 `tensor_list` 에 복사.
- `dist.barrier(group)`: `group` 내의 모든 프로세스가 이 함수에 진입할 때까지 `group` 내의 모든 프로세스를 멈춤(block).
아래에서 `barrier` 빼고 나머지 6개 자세히 볼 예정.
Broadcast
특정 `tensor`를 `src` rank에서 지정한 process group `group`으로 (지정 안하면 기본 group으로) 전달한다.
좀 더 OS 관점에서 말하자면, 만약 현재 process가 rank 0라면 아래 코드를 만났을 때 tensor를 전송(send)해야 하고,
만약 현재 process가 rank 0이 아니라면 아래 코드를 만났을 때 전송된 tensor를 받아야(receive) 한다.
torch.distributed.broadcast(tensor, src, group=None, async_op=False)그림의 예시에서는, rank 0 process의 tensor t0를 다른 process들 (rank 1~3)에게 전달한다.

Scatter
`src` process: `scatter_list`에 있는 n 개의 tensor를 `group` 내의 n 개의 process한테 순서를 맞춰서 하나씩 흩뿌린다(scatter).
ith process : `src` process가 뿌린 `scatter_list[i]` tensor를 `tensor` 변수에 저장한다.
torch.distributed.scatter(tensor, scatter_list=None, src=0, group=None, async_op=False)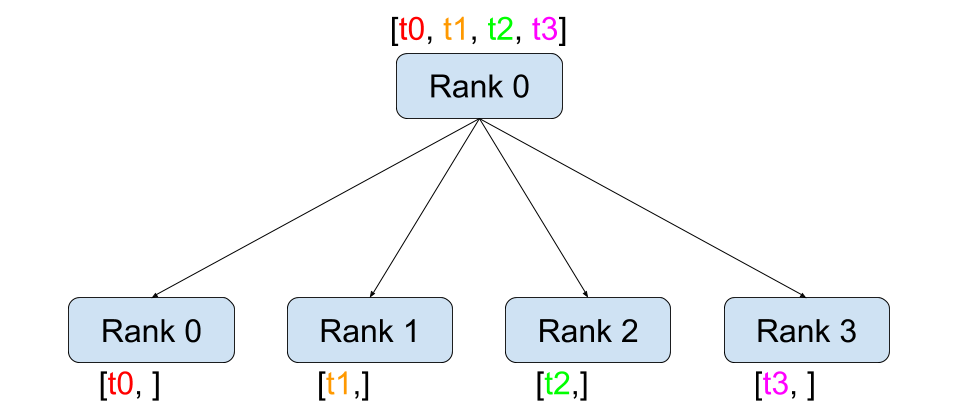
Example
# Note: Process group initialization omitted on each rank.
import torch.distributed as dist
tensor_size = 2
t_ones = torch.ones(tensor_size)
t_fives = torch.ones(tensor_size) * 5
output_tensor = torch.zeros(tensor_size)
if dist.get_rank() == 0:
# Assumes world_size of 2.
# Only tensors, all of which must be the same size.
scatter_list = [t_ones, t_fives]
else:
scatter_list = None
dist.scatter(output_tensor, scatter_list, src=0)
# Rank i gets scatter_list[i]. For example, on rank 1:
output_tensorGather
scatter 통신의 반대로, 각 process의 `tensor`를 `dst` process의 `gather_list`에 보낸다.
i th process : 자신이 보내고 싶은 `tensor`를 보낸다.
`dst` process : `gather_list[i]`에는 i th process가 보낸 `tensor`가 저장된다. 그렇게 `gather_list`에 각 process가 보낸 tensor를 저장할 수 있다. 자기가 `dst` process라면 `gather_list`에 저장 받을 변수 주소를 꼭 써야겠지.
torch.distributed.gather(tensor, gather_list=None, dst=0, group=None, async_op=False)
Reduce
각 processor가 다 갖고 있는 (그러나 값은 다른) 특정 `tensor`를 `dst` process로 전달한다. 전달할 때 `op`에 지정한 연산을 수행한 값을 보낸다.
`dst` process는 `tensor` 변수에 in-place로 연산된 값을 받는다.
`op` 연산은 SUM, PRODUCT (element-wise 곱), MIN, MAX 중에 선택해서 쓸 수 있다 (ex. `torch.distributed.ReduceOp.SUM`).
torch.distributed.reduce(tensor, dst, op=<RedOpType.SUM: 0>, group=None, async_op=False)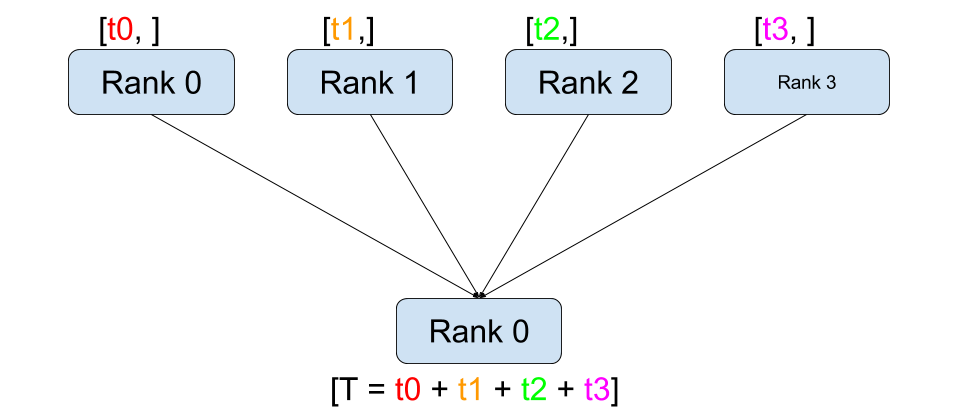
All-Reduce
reduce의 확장 버전. 특정 `dst` process만 연산된 값 T를 받는 게 아니라, `group` 내 모든 process가 동일한 값 T를 `tensor`에 전달 받는다.
torch.distributed.all_reduce(tensor, op=<RedOpType.SUM: 0>, group=None, async_op=False)
All-Gather
gather의 확장 버전.
`group` 내의 각 process의 `tensor`를 전달하면, 각 process의 `tensor_list`에 전달된 tensor들을 받는다.
torch.distributed.all_gather(tensor_list, tensor, group=None, async_op=False)
'분산 ML' 카테고리의 다른 글
| Distributed KAN (0) | 2024.06.17 |
|---|---|
| DeepSpeed X ResNet-18 (0) | 2024.05.23 |
| DeepSpeed 문제 분석 (0) | 2024.05.16 |
| [Architecture] Flynn's Taxonomy (0) | 2024.04.28 |
| DeepSpeed 소스 코드 분석 (0) | 2024.04.24 |