2026. 4. 24. 00:28ㆍ분산 ML
참고 사이트:
- https://github.com/deepseek-ai/DeepEP
- DeepEP - https://www.deepep.org/
- https://discuss.pytorch.kr/t/deepep-mixture-of-experts-feat-deepseek/6212
참고논문 : UCCL-EP - https://arxiv.org/pdf/2512.19849
MoE 상황에서 더 빠른 Expert Parallelism를 위한 Communication Library.
MoE 장인 DeepSeek AI에서, NVLink 및 GPUDirect RDMA를 통한 저지연 통신을 활용해 MoE & Expert Parallelism 전용 Comm. Library를 만들었다. MoE의 dispatch / combine 연산의 all-to-all 통신을 최적화해주는 고성능 GPU kernel을 제공하고, FP8 연산이나 heterogeneous domain (e.g., NVLink domain vs InfiniBand domain) 간 통신도 지원한다.
MoE Forward Pass in Expert Parallelism
DeepEP가 필요해진 문제 상황을 이해하려면, MoE가 어떻게 진행되는지, ragged 방식과 padding/drop 방식의 차이에 대한 이해부터 필요하다.
예를 들어 Expert가 128개, 그 중에 active experts가 4개인 MoE 구조 (아래 GPT-OSS 120B 구조)를 EP=8로 분산학습 한다고 생각해보자. 그러면 한 GPU에는 experts가 128/8=16개씩 올라간다.
처음에 한 batch로 들어온 input batch (batch size $B$ x token length $N$ x hidden dim size $H$)가 먼저 Attention block을 통과하고 residual connection을 거쳐서 MoE block에 도달한다.
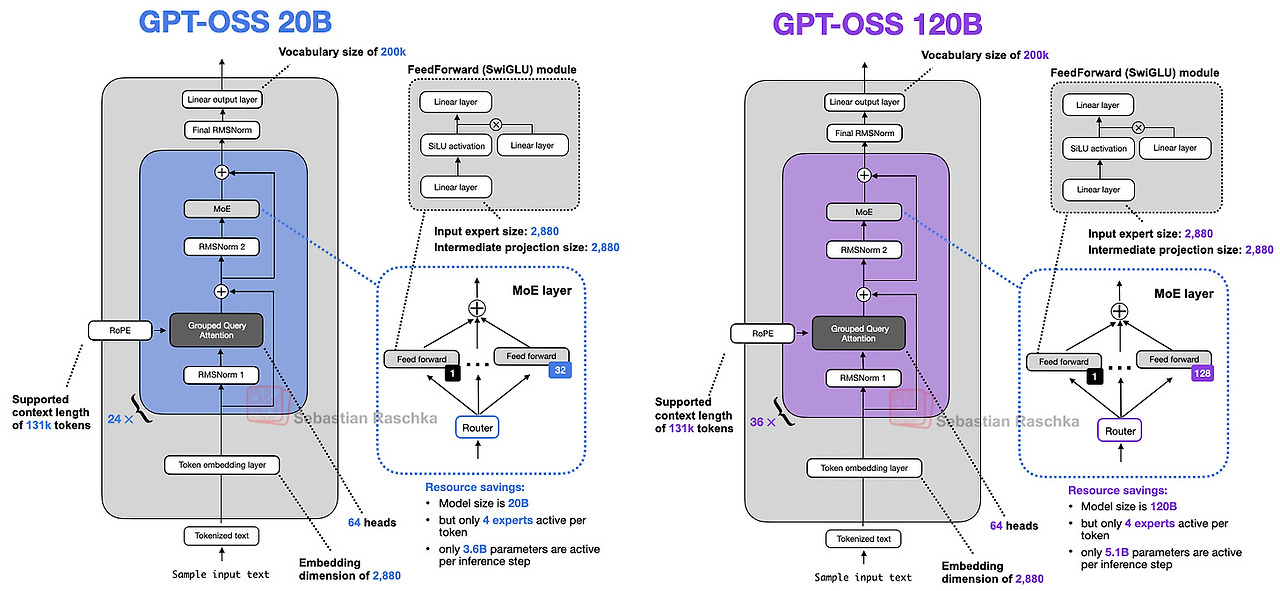
그러면 MoE layer의 첫 단추, Router에서는 이 input batch를 token-wise하게 바라보고 (dim flatten: $ B \times N \times H \rightarrow BN \times H$ ), 각 token마다 어느 expert로 보내야 할지를 결정한다.
1) Router
즉 Router는 $BN \times H$ 를 input으로 받아서 gate weight score가 가장 큰 top-$k$ experts의 index와 score을 반환한다 (index와 score 둘다 $BN \times k$ 크기). 여기서 $k$는 활성화되는 experts 수, 즉 우리 상황에서는 $k$=4가 되겠다.
2) Dispatch
그러면 이제 어떤 experts로 보내야 할지 알았으니, 진짜 보내야 한다.
요즘 기본으로 쓰는 통신 방식은 (Dropless) Ragged tensor / Concat 방식이다.
Expert 별 router에 의해 할당된 token 수가 다 다를텐데, 이걸 굳이 똑같게 맞추려 하지 말고 variable size로 (GPU i가 Expert j에게 보내는 token 수 x H)만큼씩 All2All 통신을 한다.
통신 후 각 GPU의 각 expert는 tokens_per_expert x $H$ 만큼의 input을 가지게 된다.
Drop/Padding 방식
$BN \times H$ 였던 dimension shape을 expert 기준으로 $E \times C \time H$ 로 재배열한다 (group-by expert):
- $E$: 총 expert 수. 이 사례에서는 $E=128$.
- $C$: 각 expert가 품을 수 있는 최대 token 수 (capacity).
- $H$: hidden dimension.
그러니까 각 expert에게 배정된 token들을 줄 세워서 $C$ 만큼 자르고 남은 token들은 drop. 만약에 배정된 token 수가 $C$보다 작은 expert 행의 경우에는 $C$ dimension에 맞게 padding 처리한다.
그러면 이제 i-번째 row $C\times H$를 expert i에게 발송 (dispatch)한다.
이때 모든 GPU에서 $ECH$ 크기의 padding처리된 sparse한 input을 발송하고, 각 GPU에 experts가 16개씩 있다고 했으니까, sparse All-to-All 통신을 하게 된다.
통신 후 각 GPU는 자기가 맡은 experts 수 ($E_{local}$. 이 사례에서는 $E_{local}=16$)만큼의 input을 받기 때문에 $E_{local}\times C \times H$ 만큼의 input을 가지고, 각 expert는 $C \times H$만큼의 input을 가진다.
Megatron-LM 코드 기준, 기본값은 Ragged (dropless) 방식이다. Drop/Padding은 `--moe-expert-capacity-factor` 설정 시 활성화되고, capacity 초과 토큰은 probs 또는 position 정책으로 drop된다.
| 항목 | Ragged (Dropless) 방식 | Padding (Capacity-based) 방식 |
| 기본 아이디어 | expert별 token 수를 그대로 유지 (variable length) | 모든 expert 입력을 동일한 크기(C)로 맞춤 |
| 데이터 형태 | variable-sized tensor (ragged) | fixed-sized dense tensor |
| 통신 방식 | 각 expert별 서로 다른 크기로 All-to-All | 동일 크기 기준으로 All-to-All |
| 추가 정보 | offset / index 등의 metadata 필요 | metadata 거의 불필요 |
| 메모리 효율 | +) 높음 (불필요한 padding 없음) | 낮음 (padding으로 낭비 발생) |
| compute 효율 | +) 높음 (실제 token만 연산) | 낮음 (padding까지 연산) |
| load imbalance 대응 | token drop 없고, throughput이 줄어듦. | capacity 초과 시 token drop. |
| throughput | workload에 따라 다름 (irregularity 영향) | +) 안정적 (uniform workload) |
| 사용 사례 | training (특히 최신 MoE 모델) | inference 환경 |
그리고 각 expert는 자기에게 할당된 input에 대해 FFN 연산을 수행한다.

3) Combine
top-k routing (우리 상황: $k$=4) 기준으로 보면, 각 토큰은 expert E1, E2, E3, E4에게 할당되어 각 $H$ 길이만큼의 FFN output을 얻은 상황이다. 이제 이 experts 연산 결과를 다시 합쳐야 (combine) 한다.
dispatch 때와 정반대로 reverse all-to-all 통신으로 combine.
각 token이 expert 4개로부터 얻은 결과를 weighted sum으로 합쳐 하나의 output을 가지게 된다.
Problem
그런데 위 상황의 dropless ragged 방식은 전통적인 NCCL All-to-All에 잘 맞지 않는다.
전통적인 CC (collective comm.)는 각 GPU가 미리 정해진 크기의 buffer를 모든 GPU와 교환하는 구조인데, 따라서 보내기 전에 각 peer 간에 보낼 data 크기를 미리 알고 있어야 하고, data shape이 가능하면 균일해야 한다.

그런데 dropless ragged 방식은 expert마다 할당되는 token 수가 dynamic하게 결정되니까 data 크기가 그때그때 매번 다르고 균일하지도 않다 (fragmented GPU-GPU transfer). 그럼 어떡하냐?:
- 균일한 조각 단위(tensor)으로 잘게 쪼개서 여러 번 통신하기
- -) 이러면 NIC의 WQE (work queue entry)가 폭증...! -> latency + overhead 증가.
- expert 별로, token input들을 하나의 contiguous buffer로 packing해서 보내기
- -) 통신 latency 자체는 효율적이나, packing/unpacking하는데 overhead 생김.
- Dropless Ragged 방식 포기하고 Padding/Drop 방식 택하기
- -) 위 더보기란에서 표로 정리했듯, padding/drop 방식은 padding으로 인한 추가 overhead와 drop으로 인한 학습 불안정성이 발생한다.
아무튼, 이러나 저러나 비효율적이다. 그래서 이 old NCCL All-to-All 대신 MoE ragged 방식에 찰떡으로 맞는 communication library가 없을까? 해서 나온 게 바로바로~~~ DeepEP (딥 이피 라고 읽음..ㅎ)이다!
DeepEP: GPU-initiated Token-level Communication
GPU thread가 host OS를 거치지 않고 NVIDIA IBGDA (InfiniBand GPUDirect Async) & NVSHMEM (NVIDIA Shared Memory)를 활용해서 NIC한테 direct하게 transfer command를 날린다 (submit한다).
DeepEP는 inference decoding용 low-latency mode와 training용 high-throughput mode 두 가지 모드를 제공한다.
low-latency mode에서는 IBGDA + NVSHMEM을 활용.
High-throughput mode에서는 CPU-initiated RDMA를 활용.

- GPU-initiated RDMA (IBGDA)
- 기존 EP 방식: CPU → NIC에게 send/recv 요청, GPU는 메모리만 제공
- DeepEP 방식: GPU thread (SM)가 직접 NIC에게 요청, CPU 개입 없음
- NVIDIA GPUDirect Async (IBGDA) 기술을 통해 GPU kernel 내부에서 통신을 직접 실행한다.
- +) 빠름.
- Token-level Communication Kernel
- 기존 EP 방식: large batched All-to-All
- DeepEP 방식: token-level fine-grained transfer.
- token 단위로 send/recv. => dynamic routing 그대로 반영 가능,
- +) packing/unpacking 비용 제거 => latency $\downarrow$, throughput $\uparrow$
- 참고) latency=output 한 번 내는데 걸리는 시간 / throughput=단위 시간에 몇 개의 output을 내는지. 한번 output 내는데 소요되는 end-to-end time은 길지만 병렬처리가 뛰어난 경우에는 latency가 높고 throughput도 높다.
- Asynchronous & Overlap Execution
- 기존 EP 방식 (Drop/Padding): 모든 token이 한꺼번에 도착 후, 한번에 FFN 실행.
- DeepEP 방식: 일부 token이 도착하면 전체가 sync되기를 기다리지 않고 streaming 방식으로 바로 FFN 실행.
- HOW? comm. kernel이랑 computation kernel이랑 섞지 않고, GPU SM 일부를 아예 communication kernel에 할당.
- hook-based comm.-computation overlapping method
- +) training / inference workload에 맞게 이 kernel 할당 비율을 tuning 가능. (SM Resource Control)
- +) expert load imbalance 문제로 인해서 slow expert가 전체를 기다리게 하는 문제를 완화해줌. 기존 synchronous 방식은 barrier를 걸어서, 모든 expert가 자기 token을 받을 때까지 기다렸다가 다같이 FFN compute를 시작하고, 모든 experts가 FFN compute를 끝나야만 combine A2A 통신을 진행한다. 반면 이 streaming 방식은 먼저 token 받으면 먼저 compute 시작할 수 있고, FFN 끝난 token은 바로 async하게 combine 전송할 수 있다.
- => +) 빨라짐.
한 마디로 정리하면, DeepEP 덕분에 같은 MoE 연산에 대해 더 빠른 처리가 가능해졌다.
기존 NCCL에서는 `총 시간 = Dispatch Comm. + FFN Compute + Combine Comm.` 으로 걸렸다면, DeepEP에서는 Comm kernel과 Compute kernel을 따로 구분하니까, 대강.. `총 시간 = max(Dispatch+Combine Comm., FFN Compute)` 으로 걸린다고 보면 됨.
'분산 ML' 카테고리의 다른 글
| NVIDIA GPUDirect Async (IBGDA) (0) | 2026.06.04 |
|---|---|
| Context Parallelism v.s. Sequence Parallelism (Megatron-LM 기준) (0) | 2026.05.27 |
| Distributed Optimizer ↔ FSDP 차이 (Megatron 코드 기준) (0) | 2026.04.15 |
| CUDA Multicast (0) | 2026.04.13 |
| DISTMM: Accelerating Distributed Multimodal Model Training (0) | 2026.03.18 |