2026. 3. 13. 10:51ㆍ분산 ML
논문 (ArXiv'23) : DeepSpeed Ulysses: System Optimizations for Enabling Training of Extreme Long Sequence Transformer Models
DeepSpeed Ulysses: System Optimizations for Enabling Training of Extreme Long Sequence Transformer Models
Computation in a typical Transformer-based large language model (LLM) can be characterized by batch size, hidden dimension, number of layers, and sequence length. Until now, system works for accelerating LLM training have focused on the first three dimensi
arxiv.org
사이트 : https://github.com/deepspeedai/DeepSpeed/tree/master/blogs/deepspeed-ulysses
DeepSpeed/blogs/deepspeed-ulysses at master · deepspeedai/DeepSpeed
DeepSpeed is a deep learning optimization library that makes distributed training and inference easy, efficient, and effective. - deepspeedai/DeepSpeed
github.com
이 당시 (2023년) 분산학습 기법은 크게 3 가지 (DP / TP / PP)로 나뉘었다. 그런데 얘네들은 long sequence Transformer model에 특화된 기법들이 아니다.
Q. long sequence를 다루는 transformer 모델이 왜 중요하냐?
A. "긴 문서에 대해 통합적으로 한번에 context를 이해하는 능력"이 어디에 중요할까?
- 긴 문서 (e.g., 책 한 권) 기반 요약 / reasoning / RAG 이런데에 잘 쓰임.
- video generation task에서도 spatial / temporal domain에서 하나의 video를 하나의 긴 context라고 볼 수 있음. -> 하나의 video를 통합적으로 이해하는 능력.
- multimodal 상황에서도, 일단 이미지가 들어가면 기본적으로 먹고 들어가는 token 수가 많아짐. 이미지를 보고 reasoning하려면 모델 자체가 long context를 다룰 줄 알아야 함.
- structure biology, large molecular simulation, weather forecasting 같은 과학 AI 분야에도 활용성이 높음.
-) Long sequence transformer model에 기존 분산학습 기법들을 적용했을 때의 한계점: sequence dimension으로 scaling이 안됨. 다시 말해, 'sequence 길이 늘어나면 그냥 지금 분산학습 구조에 GPU 하나 더 추가하면 되잖아~' 같은 발상이 (안되는건 아니겠지만 구현하기가) 어려움.
Previous Works: Sequence Parallelism
=> 그래서 sequence (tokens)-dimension으로 자르는 Sequence Parallelism (SP)이란 게 나왔다.
- Related Work 1) Sequence Parallelism: Long Sequence Training from System Perspective
- layer의 hidden_dim 차원으로 모델을 쪼개는 TP와 달리, Input을 token dim으로 분리한다. 그래서 엄밀히 말하면 모델은 쪼개지지 않고 각 device에 replica로 올라간다. 오히려 DP랑 비슷한 느낌. Transformer를 위한 DP 느낌.
- 자세한 내용은 이 글 참고 -> 2026.03.15 - [분산 ML] - Sequence Parallelism: Long Sequence Training from System Perspective

- Related Work 2) Reducing Activation Recomputation in Large Transformer Models
- 기본 Megatron TP 구조에서, TP가 적용 안되는 Dropout, LayerNorm 같은 부분에 SP 적용. 따라서 중간 activation 값들도 device에 나눠 저장하게 되니까 전체 memory 요구량이 줄어듦. -> 원래는 이 activation 저장 용량이 커서 activation recomputation 같은 기법을 적용했는데, 이제 굳이 필요가 없어진,,

-) 근데 기존 SP는 memory, communication 차원에서 여전히 비효율적이다.
- Communication Volume이 여전히 크다. Memory efficiency도 여전히 크다.
- ColAI-SP (Related Work 1)의 경우 기존 self-attention 대신 특별한 ring self-attention을 사용해서 불편하다 (?).
- 기존 분산학습 코드가 좀 드러움 (=error prone, intrusive) -> 사용성이 떨어짐. (이거 실제로 돌려본 사람 입장에서 완전 인정ㅎ,, 특히 Megatron. 사용성 측면에서는 torchtitan이 탑임.)
=> 이 논문:
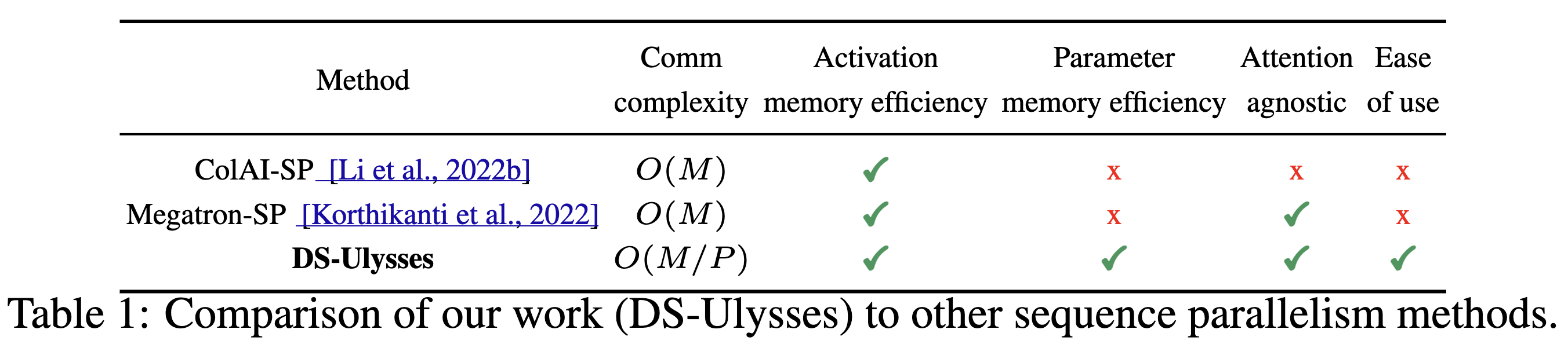
- 기존 두 SP 방식에 비해 communication volume ($M$)을 GPU 수 ($P$)에 비례하게 줄였다.
- FSDP (DeepSpeed ZeRO)를 짬뽕해놔서 memory efficiency도 올렸다.
Method

기본 Transformer (Multi-head attention) 병렬연산 구조:
- QKV 연산까지는 각 GPU에서 하든, 한 GPU에서 하든 해서 암튼 각자 연산함.
- 그리고 각 GPU가 각각 서로 다른 head를 담당해서 attention 연산. (head-wise 병렬 처리)
- 그 다음에 all-gather를 하든 gather를 하든 해서 head 별 P 값($P_h=S_h\cdot V_h$)을 한 GPU로 모은 다음에 마지막 $W_o$ 곱해서 output $O$ 만듦.
여기에 Sequence Parallelism를 적용해보면, 처음에 input $x$를 $(N, d) \rightarrow (N/P, d)$로 분할하는 건 모든 SP 방식들에서 동일.
그런데 그 뒤에 어떤 임베딩을 어떤 방식으로 통신할거냐에서 조금씩 다름.
기존 SP 구조에서는 K랑 V embedding을 ring-style P2P로 모든 GPU가 값을 공유했다 :
- Attention 연산 전에, K embedding을 ring-style P2P로 GPU들 간 값 공유.
- Communication Volume: $Nd/P \times (P-1)=O(Nd) $ (각 GPU가 총 P-1개 GPU로부터 Nd/P 크기의 데이터를 받음.)
- Communication Time: P2P 통신시간 x (P-1) 회
- Memory Complexity: $O(Nd/P)$
- attention score에 V 곱하기 위해, V embedding을 ring-style P2P로 GPU 간 공유.
- Communication Volume / Time / Memory Complexity는 K embedding 때랑 동일.

그런데 이 DeepSpeed-Ulysses는 ring-style P2P 대신 all2all 통신을 한다고 한다. 그리고 특이한 게, 이 논문에서는 all2all 통신을 할 때, 각 local에 원래 $(N/P, d)$ 차원의 tensor가 있었다면 (sequence-wise splitted), 이걸 all2all 통신을 통해 head-wise split으로 바꿔서 $(N, d/P)$ 차원의 tensor를 가지게 한다. 그러므로 통신 전후로 각 GPU가 가지는 memory 요구량은 동일한데, 통신량은 기존 ring-style P2P에 비해 줄어든다.
| All-Gather | Ring-style P2P | 이 논문의 All-to-All 통신 | |
| 기본 아이디어 | 각 GPU shard를 모두 모아서 full tensor 생성 | tensor block을 GPU 사이에서 순환 전달하면서 계산 | 쪼개는 차원을 다르게. $(N/P, d) \rightarrow (N, d/P)$ |
| 통신 패턴 | 각 GPU i가 xi 들고 있을 때, All-Gather 한 번으로 → GPU0: [x0 x1 x2 x3] GPU1: [x0 x1 x2 x3] GPU2: [x0 x1 x2 x3] GPU3: [x0 x1 x2 x3] 모든 GPU가 full tensor 보유 |
GPU0 → GPU1 → GPU2 → GPU3 → GPU0 총 N-1번의 P2P가 발생하고, 각 step 마다: 1) receive xi 2) compute (e.g., attention A 연산) 3) send xi |
각 GPU i가 full tensor $X$의 $X_{(i,:)}$를 들고 있었다면, all-to-all 통신으로 $X_{(:,i)}$를 가지게 됨. |
| Output Memory | V (V: full tensor 크기) | V/P (P: GPU 수) | V/P |
| 중간 peak memory | V (어쨌든 full tensor를 모아야 하기에) | V/P (가장 streaming스러운. 메모리 절약형) | V/P와 V 사이. (차원을 바꾸려면 어쨌든 V/P보다는 많이 필요.) |
| Comm. Volume | O(V) (각 GPU가 $V/P$ 크기 데이터를 보내고, $V\cdot (P-1)/P$ 만큼의 데이터를 받음.) | O(V) (각 GPU가 $V/P \cdot (P-1)$ 만큼의 데이터를 보내고/받음.) | O(V/P) (각 GPU가 $V/P \cdot (P-1)/P$ 만큼의 데이터를 보내고/받음. |
자세한 순서를 보면:
- Attention 연산 전에, Q, K, V embeddings를 sequence-wise에서 head-wise로 all-to-all 재분배.
- Communication Volume: $3Nd/P=O(Nd/P) $ (각 GPU가 3Nd/P 크기의 데이터를 전송.)
- Communication Time: All2All 통신시간 x 1회 (아무래도 기준 시간은 All2All이 P2P보다 느리긴 하겠지)
- Memory Complexity: $O(Nd/P)$
- 각 GPU에서 자기에게 해당되는 head에 대해 self-attention 연산.
- MLP block을 sequence parallel하게 처리하기 위해서 output $P_h=S_hV_h$를 다시 head-wise -> sequence-wise로 all-to-all 재분배.
- Communication Volume: $Nd/P=O(Nd/P) $ (각 GPU가 Nd/P 크기의 데이터를 전송.)
- Communication Time: All2All 통신시간 x 1회
- Memory Complexity: $O(Nd/P)$
+ DS-Ulysses는 DeepSpeed ZeRO-3를 결합한다. model states나 gradient를 각 GPU에 쪼개 담는 ZeRO 방식(FSDP)을 적용해서, 전체 DP x SP groups에 걸쳐서 분할하고, 연산에 필요한 순간에만 all-gather를 통해 분할된 조각들을 가져온다.
A. ring-style P2P vs all2all (all-gather) 통신 차이:
한마디로, ring-style P2P가 all-gather에 비해 시간이 더 오래걸리고 대신 memory usage를 줄인 버전이라고 보면 될듯. 약간 online streaming 버전의 all-gather 느낌.
| All-Gather | Ring-style P2P | |
| 기본 아이디어 | 각 GPU shard를 모두 모아서 full tensor 생성 | tensor block을 GPU 사이에서 순환 전달하면서 계산 |
| 통신 패턴 | 각 GPU i가 xi 들고 있을 때, All-Gather 한 번으로 → GPU0: [x0 x1 x2 x3] GPU1: [x0 x1 x2 x3] GPU2: [x0 x1 x2 x3] GPU3: [x0 x1 x2 x3] 모든 GPU가 full tensor 보유 |
GPU0 → GPU1 → GPU2 → GPU3 → GPU0 총 N-1번의 P2P가 발생하고, 각 step 마다: 1) receive xi 2) compute (e.g., attention A 연산) 3) send xi |
| 통신 방식 | Collective communication | Point-to-point streaming |
| GPU topology | broadcast / tree | ring |
| 통신 단계 | 1 step | N-1 steps |
| 통신 후 tensor | full tensor 크기 | 여전히 local shard |
| latency | 낮음 | 높음 (N-1 iteration) |
비교하면,
| ColAI-SP (첫 SP 논문) | Megatron-SP (TP+SP) | DS-Ulysses (FSDP+SP) | |
| 통신 방법 | ring-style P2P | all-gather, reduce-scatter | gather, scatter |
| Comm. Volume | $2Nd$ | $4Nd$ | $4Nd/P$ |
Strength
+) 기존 방법들보다 communication volume이 더 줄었다.
+) ring-style P2P 때처럼 특이한 연산구조를 하지 않아도 (?) 된다.
'분산 ML' 카테고리의 다른 글
| DISTMM: Accelerating Distributed Multimodal Model Training (0) | 2026.03.18 |
|---|---|
| Sequence Parallelism: Long Sequence Training from System Perspective (0) | 2026.03.15 |
| Run GPT3 on Megatron (0) | 2024.06.18 |
| Distributed KAN (0) | 2024.06.17 |
| DeepSpeed X ResNet-18 (0) | 2024.05.23 |